 BOM
BOM Cart()
Cart() English
English Russia
Russia Korean
Korean
Nvidia has announced the Vera Rubin platform, a broad suite of seven new chips designed to power the next generation of agentic AI factories. They include the Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 SuperNIC, BlueField-4 DPU, Spectrum-6 Ethernet switch, and the Groq 3 LPU.

Nvidia's Vera Rubin family. Image used courtesy of Nvidia
By combining all of these chips into a single coherent supercomputer, the company hopes that product developers can confidently manage the entire AI lifecycle, from pretraining to real-time agentic inference.
The Vera Rubin Family
Nvidia designed the Vera Rubin NVL72 rack to train large mixture-of-experts models with a quarter of the GPUs required by previous Blackwell-based systems. The rack has 72 Rubin GPUs and 36 Vera CPUs connected via NVLink 6, which provides 1.8 TB/s of coherent bandwidth, seven times the bandwidth of PCIe Gen 6.
For inference-heavy workloads, the company released the Groq 3 LPX rack, which has up to 35 times higher throughput per megawatt. These LPUs all have 128 GB of on-chip SRAM and 640 TB/s of scale-up bandwidth, allowing a fleet of processors to operate as a single, deterministic accelerator for trillion-parameter models.
Nvidia positions the Vera CPU as the primary orchestrator in this ecosystem, purpose-built to handle reinforcement learning and environment simulation tasks essential to agentic AI.
Customers have access to 88 custom Nvidia-designed "Olympus" cores, each capable of running two tasks simultaneously via Spatial Multithreading. The CPU has a low-power memory subsystem using LPDDR5X to deliver 1.2 TB/s of bandwidth, doubling the performance of general-purpose CPUs while consuming half the power.
In a standard rack configuration, 256 liquid-cooled Vera CPUs can support over 22,500 concurrent independent environments for testing and validating AI-generated results.

The Vera CPU rack. Image used courtesy of Nvidia
To help customers manage the massive datasets required for long-context reasoning, Nvidia created the BlueField-4 STX architecture. The modular design enables storage providers to expand GPU memory with a high-performance context layer, delivering up to 5x the token throughput of traditional storage. The STX platform harnesses the BlueField-4 processor to ingest data at twice the speed of prior architectures while improving energy efficiency by 4x. It also uses the new DOCA Memos framework to provide dedicated key-value (KV) storage, enabling AI agents to remain coherent during multi-turn interactions.
Understanding Context Memory in Large-Scale Inference
For large language models and agentic systems, the system stores intermediate data from ongoing conversations or reasoning chains in context memory. During inference, the model generates a KV cache containing the mathematical representations of all previous tokens in a session. As the context window grows to millions of tokens, the size of this KV cache exceeds the capacity of standard on-chip GPU memory.
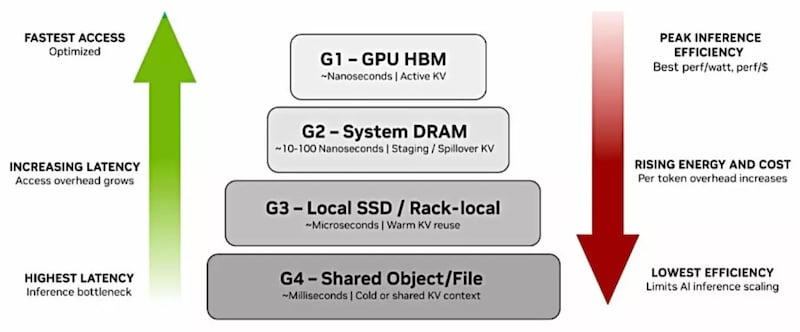
KV cache stack, in order of access and inference efficiency. Image used courtesy of Blocks & Files
When the KV cache exceeds the available GPU memory, the system must offload the data to external storage. Conventional storage architectures, designed for general-purpose file access, often add significant latency and bottlenecks during this transfer. This creates stalls, where the GPU sits idle, waiting for the needed context data to be retrieved before it can generate the next token.
Context memory storage architectures solve this cache problem by creating a specialized high-speed tier between the GPU and bulk storage. By using high-bandwidth interconnects and specialized protocols to manage KV cache data specifically, the GPU can access distant data as if it were local. This is vital for agentic AI because an autonomous agent may need to remember instructions from thousands of steps prior or reference massive external documents to complete a task without losing speed or accuracy.
The Future of AI Factories
POD-scale, liquid-cooled infrastructure helps organizations deploy more compute power within fixed-power constraints. By using the DSX platform, Nvidia hopes users can dynamically provision power and operate 30% more infrastructure in the same footprint.
Vera Rubin products, including the Vera CPU and BlueField-4 STX, are in full production. They will be available through partners, including major cloud providers and system manufacturers, in the second half of this year.

EA-CHIP INDUSTRY CO., LIMITED
-
Tel
+86 180 2549 2789 -
Wechat
